Creating An Experiment
How about we start creating some experiments? At the top of the dashboard, you will find the New Experiment button. Here you will be able to fine tune, edit and start your experiment.
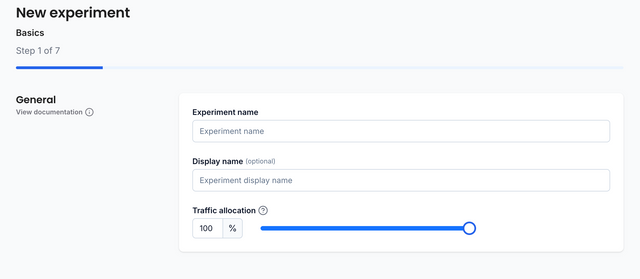
Basics
The Basics step is where you will set some of the most important values for your experiment. The experiment name, the traffic allocation and the analysis type.
Experiment Name
The experiment name can be anything that you want! As it will be used in your
code, we recommend using a keyword-like name with underscores. For example,
large_homepage_carousel.
Traffic Allocation
The traffic allocation is the total amount of audience who will experience the experiment, including the control group. Usually, this is kept at 100% unless the change is considered dangerous. In which case, you could start it at 10%, move it up to 50% and eventually to 100% as you grow more confident in the change.
Variants
The variants section is where you will choose your amount of variants, the percentage of traffic that each variant will have, your variant names and set any variant variables which can be used in your code.
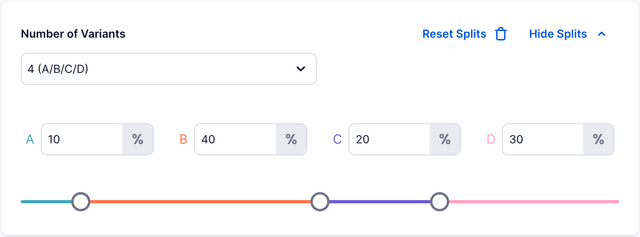
Variant Split Manager
The Variant Split Manager is where you can select your number of variants and the split percentage across them.
You can have up to 4 variants at any one time and your split percentage can be whatever you want. But note, the split percentage cannot be changed after an experiment has started running without biasing the data. If you wish to ramp up an experiment, it's better to use the traffic allocation option instead.
The more variants you have, the less traffic each variant will be exposed to and the longer it will take for the experiment to finish.
For a multi-variant experiment to be eligible for Group Sequential Testing, it requires an equal split between variants (exclusing base).
Variant Variables
Variant variables can be used to automate your experiments. If you, for example, use a configuration file, you can pass a variant variable here and have it overwrite your code. See treatment variables in the SDK Documentation for more information.
Generally, we do not recommend changing variables on your control variant (Variant A).
Variant Screenshots
Screenshots can be added to each variant in an experiment, to help in identifying any changes to your UI during the experiment.
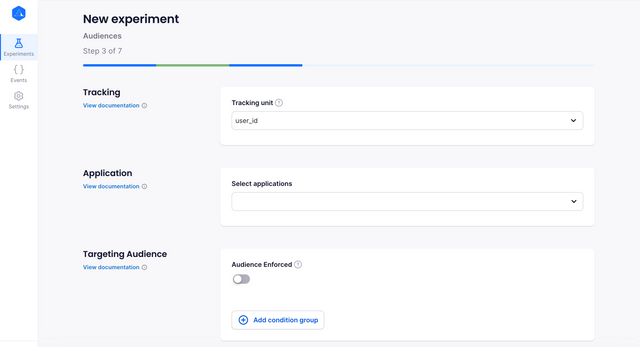
Audiences
The audiences step is where you will control who can and cannot be a part of your experiment as well as the parameters which are used to define who sees what variant.
Tracking Unit
The experiment's tracking unit is the unique identifier that will be used to assign the user to a variant.
If the experiment is to be run across multiple platforms (Such as iOS, Android,
Web, Email etc.), then this unit should be available on all of them. Most
likely, the user_id of the authenticated user.
Conversely, if you wish for a user to experience different variants depending
on their device, you could use their device_id as a unit.
Even further, to avoid experiment biases from users talking to eachother about
their experience, companies such as LinkedIn, group their users into clusters
and would use a cluster_id as their tracking unit.
You can create new tracking units in your dashboard settings.
Applications
Applications are the places where this experiment will be run. These could be "android", "ios" and "web", for example, and are also created in your dashboard settings.
Targeting Audience
Here you can define a specific audience who will experience the experiment. For example, you could decide to only test the experiment on British users. In this case you might set the filter group to:
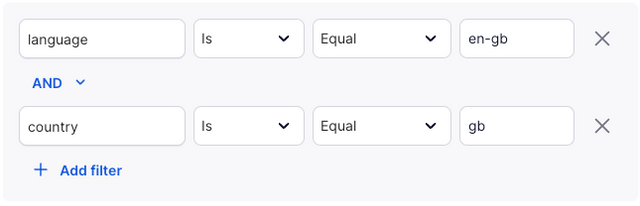
These parameters can then be passed to the SDK in your code using context attributes.
Audience Enforced
When audience enforced is on, only users in the filter groups will be able to participate in the experiment. Others will be shown the control variant, but their data will not be tracked.
When audience enforced is off, any user can participate in the experiment, but the web console may warn you that your experiment is being shown to the wrong people. This helps you and your developers to remember to add the appropriate checks in your code when a decision has been made on the experiment. For example, to only show the tested variant to British users.
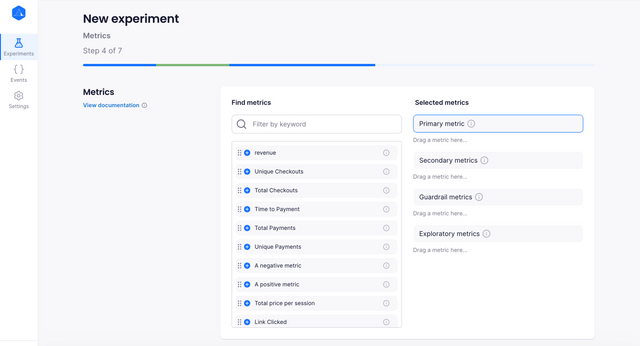
Metrics
Metrics represent the data that is affected by your experiment.
Your Primary Metric is the statistic that you will use to make a decision on your experiment.
Secondary Metrics are not used to make a decision, but they
may be affected by it. For example, if your Primary Metric is revenue_per_user it could go up because
there are more customers making purchases or it could go up because customers
are buying more expensive items. In this case, it might be useful to have
users_that_convert and number_of_purchases as secondary metrics.
Guardrail Metrics are for giving you warnings about other parts of your
business from the the Primary metric. If your new feature increases a user's
time_on_page, but also increases your page_load_time significantly - the
data may be showing you a false positive for that experiment.
Exploratory Metrics are the last of the metric types and are simply used for curiosity. They have no impact on your decision making process, but they might be interesting to look at the data of anyway.
Selecting any of the above metric types allows for them to be easily visualised on the experiment dashboard, but more metrics can always be selected at the bottom of the experiment details page.
Analysis
In this step, can choose and setup the analysis type you want to use. To choose between Group Sequential and Fixed Horizon analysis check our analysis type article.
To properly setup your experiment refer to the relevant setup guide
Metadata
The metadata step is where you can fill in details about your experiment that may help others to understand what you hope to achieve with it.
Metadata
The metadata section allows you to select the owners of this experiment, assign it to a particular team and add tags to help with searching and filtering later on. These fields may be required, optional or hidden depending on your company's platform settings.
Tags
Tags can be named anything you like. Often it can be useful to prefix your tags with the meaning of that tag. Some examples of tags could be:
stack:backendtheme:urgencylocation:navbarpsychological:trust
These allow for you to filter your experiments in the experiments list page, but they also give you an insight into why that experiment was tagged as such.
Description
When creating a new experiment, the description section acts as your contract for the test. Allowing you to define for yourself and your team why you are running this experiment, what you hope for the result to be and what will be done after any of the experiment's possible outcomes. The following are our default fields, but they may be different depending on your company's platform settings.
Hypothesis
Your hypothesis is the assumed answer to the question that the experiment is asking.
For example:
Based on the fact that the color red is one of the most visible colors in the color spectrum, we believe that red call-to-action buttons are more noticeable on screen than blue ones.
Prediction
Your prediction states what will happen if your hypothesis proves to be true.
For example:
Changing our call-to-action buttons to red will cause a higher click-through-rate to our checkout page from our visitors.
Purpose
Your experiment's purpose is the reason for why this experiment should take place. What customer or business needs are being addressed.
For example:
Optimizing the efficiency of our sales pipeline.
Implementation Details
In your implementation details, you can define the parameters of your experiment's implementation, like:
- How long it will take to implement
- What's the impact that we can expect from this implementation?
- What is the minimum impact that we need to see in order to keep this experiment?
For example:
This implementation will be completed by 12/4/2024.
We can expect an increase of up to 25% in our homepage click-through-rate.
At a minimum, we should see a 5% increase if we are to keep the change.
Action Points
Action Points are a list of actions that will be taken depending on the experiment's outcome.
For example:
If the primary metric is significantly positive we will keep the experiment.
If the primary metric is significantly negative we will drop the experiment.
If the primary metric is inconclusive we will drop the experiment.
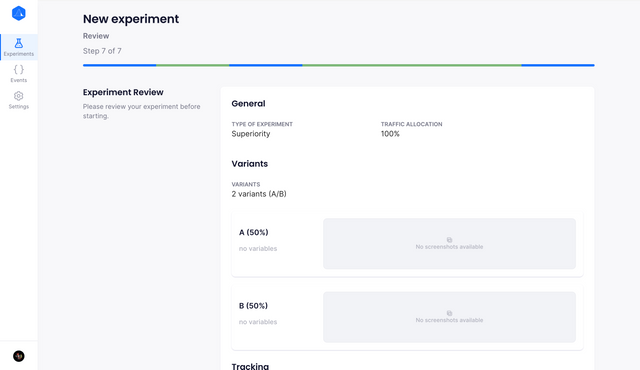
Review
The review step is where you can go over the experiment you have created and check its details before starting or saving it.
Experiment Actions
When you are happy with your experiment, you have 4 possible actions that you can take on it:
- Save it as a draft
- Save it as ready
- Start it in development mode
- Start it
Saving a draft
Saving your experiment as a draft means that you can come back to this experiment, to give it some final tweaks. When saving as a draft, all fields will still be editable when coming back to this experiment.
Saving as ready
Saving you experiment as ready is similar to saving it as a draft, but it signifies that the experiment is ready to be started. You cannot save an experiment as ready with invalid settings.
Starting in development
Starting your experiment in development allows you to test your experiment in your development environments.
An experiment in development mode will not run on a production environment, and the control variant will always be shown. This allows for you to test the implementation of an experiment before deploying it to production.
Starting
Starting your experiment will activate it in all environments and start collecting data from your users.
Up Next
The dashboard and how to read your experimentation data!